Introduction
Most research on the optimization and execution of SPARQL queries [1] over Knowledge Graphs [2] focuses on centralized use cases, in which queries are to be executed over a single dataset, in which queries can be optimized using traditional optimize-then-execute techniques [3, 4].
Due to issues in recent years involving personal data exploitation on the Web, there has been increasing interest in the decentralization of such personal data. This has materialized into various decentralization initiatives, such as Solid [5], Bluesky [6], and Mastodon [7]. What is common among these initiatives, is that they distribute personal and permissioned data across a large number of authoritative Web sources, which leads to the emergence of Decentralized Knowledge Graphs (DKGs). For this work, we limit our scope to RDF-based initiatives such as Solid, as the use of IRIs in RDF enable convenient integration of data across multiple sources. Solid enables users to host and control personal data pods, which are data sources into which hierarchies of RDF documents can be stored.
In order to find data across such massive distributions of data across the Web, there is a need for efficient query processing techniques. While techniques have been introduced that enable the execution of SPARQL federated queries [8, 9, 10], they are optimized for handling a small number (~10) of large sources [11], whereas DKGs such as Solid are characterized by a large number (>1000) of small sources. Additionally, federated SPARQL query processing assumes sources to be known prior to query execution, which is not feasible in DKGs due to the lack of a central index. Hence, these techniques are ill-suited for the envisaged scale of distribution in DKGs.
To cope with these problems, alternative techniques have been introduced recently. ESPRESSO [12] was introduced as an approach that builds distributed indexes for Solid pods which can be accumulated in a single location. This accumulated index can then be queried using keyword search to find relevant pods to a query, after which these relevant pods can be queried using federated SPARQL processing techniques. This approach depends on placing trust over personal data in this single accumulated indexer. POD-QUERY [13] is another approach that involves placing a SPARQL query engine agent in front of a Solid pod, which enables full SPARQL queries to be executed over single Solid pods. This approach does not consider query execution across multiple pods. In recent work [14], we proposed making use of Link Traversal Query Processing (LTQP) for querying across one or more Solid pods. LTQP is derived from the idea of SQL-based query execution over the Web [15, 16] and the concept of focused crawling [17, 18]. LTQP starts query execution given a set of seed sources, from which links are recursively followed between RDF documents to discover additional data to consider during query execution, In this previous work, we introduced various LTQP techniques that understand the structural properties of Solid pods, and use this to optimize LTQP in terms of the number of links that need to be followed. Such a traversal-based approach does not rely on prior indexes over Solid pods, and can query over live data that is spread over multiple pods. Results have shown [14] that non-complex queries can be completed in the order of seconds, with first results showing up in less than a second. For more complex queries in terms of the number of triple patterns, results show that more fundamental optimization work is needed into adaptively optimizing the query plan upon newly discovered information and reducing the number of links to be followed.
The focus of this article is on demonstrating the implementation of a query engine that can execute SPARQL queries across Solid pods using the LTQP techniques introduced in [14]. This query engine is open-source, and is implemented in a modular way so it can serve future research in this domain. We demonstrate this query engine through a Web-based user interface, in which preconfigured or manually created SPARQL queries can be executed across both simulated or real-world Solid pods. In the next section, we explain our approach, after which we discuss our implementation in Section 3. In Section 4, we describe our Web-based demonstration interface, after which we conclude in Section 5.
Approach
Our previously introduced approach [14] enables query execution across one or more Solid pods without the need to build any prior indexes. For this, we build on top of the Link Traversal Query Processing (LTQP) paradigm, whereby the query engine maintains an internal link queue which is initialized through a set of seed URLs. This set of seed URLs determine the starting point for traversal, and may either be user-provided, or can be derived from the URLs mentioned in the given SPARQL query. The query engine will start the process by continuously iterating over this link queue, dereferencing each link, and adding all discovered RDF triples into an internal triple source that can continuously grow. Furthermore, for each dereferenced link with resulting RDF triples, the engine finds links to other sources, which are appended to the link queue. Different strategies exist for determining these links [19, 14]. During the processing of this link queue, the actual query processing happens in parallel over the continuously growing internal triple. This processing starts by building a logical query plan using the zero-knowledge query planning technique [20], which is necessary due to the fact that LTQP has no access to prior statistical information about the data to be queried over. After that, the plan is executed following an iterator-based pipeline approach [21], which considers the execution plan as a pipeline [22] of iterator-based physical operators. This pipelined approach allows results to be returned to the end-user, even though the link traversal and query processing may still be running for a longer time. A visualization of the architecture of our approach can be seen in Fig. 1.

Fig. 1: Link queue, dereferencer, and link extractors feeding triples into a triple source, producing triples to tuple-producing operators in a pipelined query execution.
Instead of considering all possible links that are discovered in the RDF triples, we apply various Solid-specific [14] and Solid-agnostic [19] link extraction strategies. For example, all Solid pods make use of the Linked Data Platform (LDP) specification [23] to provide an overview of all RDF documents inside a pod, which may be nested in a hierarchy of containers. An example of such a container can be seen in Listing 1, which contains links to another document and two containers. In order to indicate the existence of such Solid pods, agents within the Solid ecosystem (typically persons of organizations) may link to their pods via their identifying WebID [24]. Through this WebID, agents can be uniquely identified via a URL. After dereferencing this URL, an RDF document can be returned that can contain a link to the user’s Solid pod and other basic information such as name and contact details. An example of such a WebID document is shown in Listing 2. Furthermore, Solid pods can expose a Type Index [25], which contains a list of RDF classes for which instances exist in this pod, together with links to RDF documents containing such instances. An example of such a Type Index can be seen in Listing 3, which contains entries for posts and comments.
PREFIX ldp: <http://www.w3.org/ns/ldp#><> a ldp:Container, ldp:BasicContainer, ldp:Resource;ldp:contains <file.ttl>, <posts/>, <profile/>.<file.ttl> a ldp:Resource.<posts/> a ldp:Container, ldp:BasicContainer, ldp:Resource.<profile/> a ldp:Container, ldp:BasicContainer, ldp:Resource.
Listing 1: An LDP container in a Solid data vault containing one file and two directories in the RDF Turtle serialization.
PREFIX pim: <http://www.w3.org/ns/pim/space#>PREFIX foaf: <http://xmlns.com/foaf/0.1/>PREFIX solid: <http://www.w3.org/ns/solid/terms#><#me> foaf:name "Zulma";pim:storage </>;solid:oidcIssuer <https://solidcommunity.net/>;solid:publicTypeIndex </publicTypeIndex.ttl>.
Listing 2: A simplified WebID profile in Turtle.
PREFIX ldp: <http://www.w3.org/ns/ldp#><> a solid:TypeIndex ;a solid:ListedDocument.<#ab09fd> a solid:TypeRegistration;solid:forClass <http://example.org/Post>;solid:instance </public/posts.ttl>.<#bq1r5e> a solid:TypeRegistration;solid:forClass <http://example.org/Comment>;solid:instanceContainer </public/comments/>.
Listing 3: Example of a type index with entries for posts and comments in RDF Turtle.
Implementation
Our approach has been implemented using the JavaScript/TypeScript-based Comunica SPARQL framework [26]. Following the modular architecture of Comunica, we have implemented our approach as several small modules, which allows modules to be enabled or disabled using a plug-and-play configuration system for the flexible combination of techniques during experimentation. This implementation has full support for SPARQL 1.1 queries, which consists of pipelined implementations of all monotonic SPARQL operators. As such, our system is able to execute SPARQL queries over Solid pods using a traversal-based approach. Since certain documents within Solid pods may exist behind document-level access control, our implementation supports authentication. This allows users to log into the query engine using their Solid WebID, after which the query engine will execute query on their behalf across all data the user can access.
Our implementation is available under the MIT license at https://github.com/comunica/comunica-feature-link-traversal,
and via the npm package manager as @comunica/query-sparql-link-traversal-solid.
Our implementation can be used directly within any TypeScript or JavaScript application.
Furthermore, we provide a script using which queries can be executed from the command line,
as shown in Fig. 2.
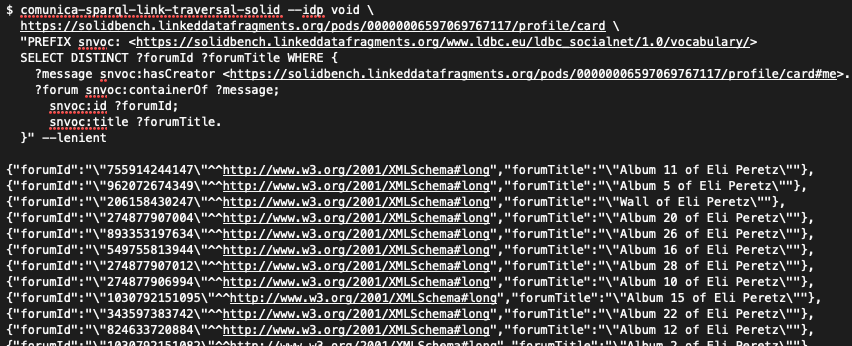
Fig. 2: Executing a SPARQL query from the command line.
Demonstration
In this section, we introduce the environment of our demonstration through a Web-based user interface, after which we discuss our main demonstration scenario.
User interface
We demonstrate our traversal-based SPARQL query engine for Solid pods through a Web-based user interface. Since our engine was implemented in TypeScript, it can be transpiled down to JavaScript, and executed client-side within any Web browser. Concretely, we make use of the Comunica jQuery widget to generated a static HTML page that contains our traversal-based query engine, as shown in the figure below. This page is hosted on https://comunica.github.io/comunica-feature-link-traversal-web-clients/builds/solid-default/, and will remain available permanently after the conference.
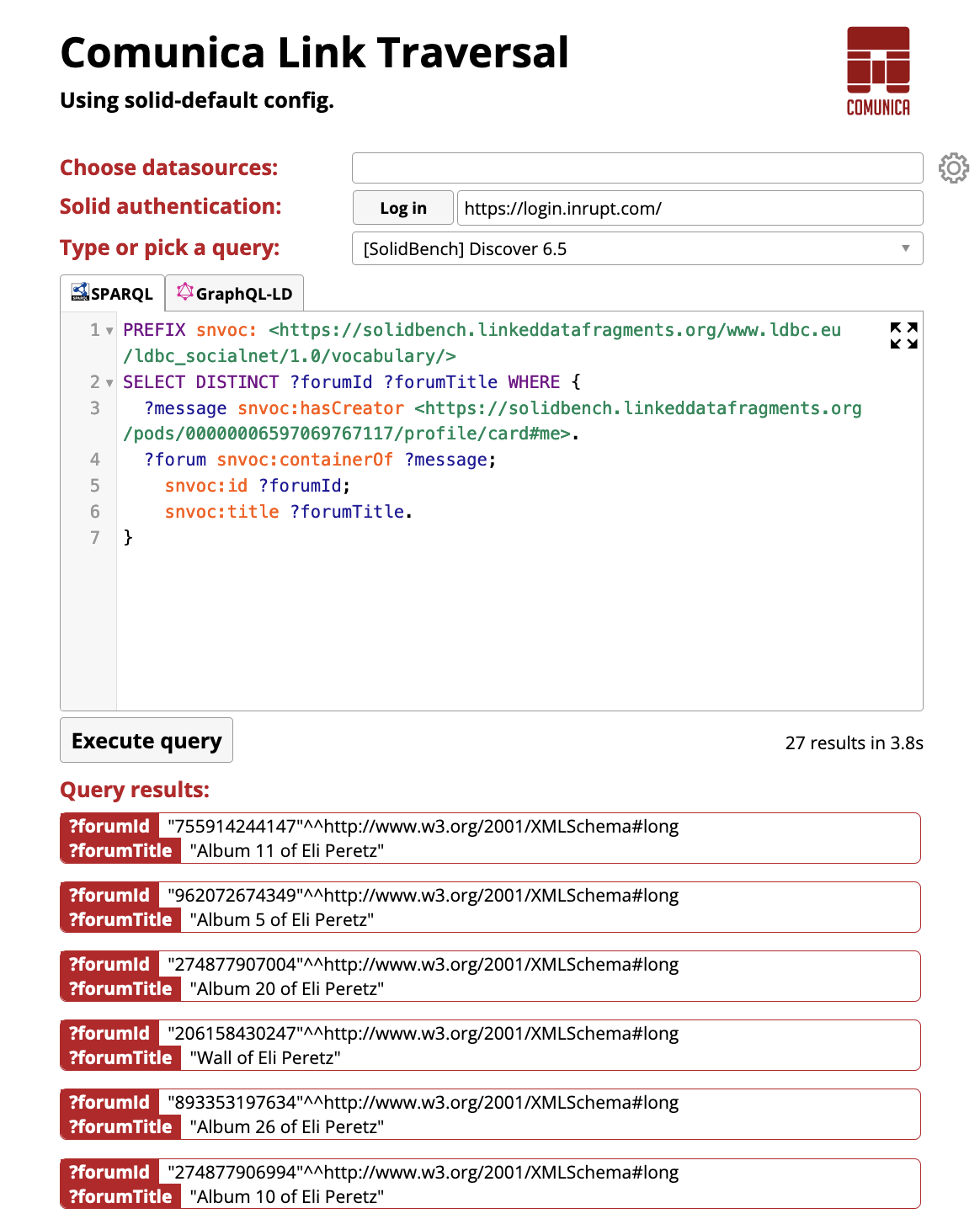
Fig. 3: Web-based user interface of our traversal-based SPARQL query engine.
Our Web-based user interface allows users to write custom SPARQL queries and select seed URLs by selecting datasources from the dropdown-list or typing in custom URLs. If no datasources are selected, the engine will fallback to a query-based seed URL selection approach, where URLs mentioned in the SPARQL query will be considered as seed URLs. Next to writing custom SPARQL queries, the user may also select one of the predefined queries from the dropdown-list. Furthermore, the user can also authenticate with a Solid account by using the “Log in” button.
After inserting or selecting a SPARQL query, the user can click on the “Execute query” button, after which the query engine will execute the query. This execution will take place in a separate Web worker process, as not to halt interactions with the user interface. Each result that is iteratively produced by the query engine will be shown immediately in the scrollable list of query results at the bottom of the page.
Scenario
Our publicly available Web-based user interface allows users to execute SPARQL queries across any existing Solid pods. Since not everyone may own a Solid pod, our primary demonstration scenario involves an environment in which we have setup a large number of simulated Solid pods.
Concretely, we host 1.531 Solid pods that were generated using the default settings of the SolidBench [14] dataset generator, which consists of 3.556.159 triples spread over 158.233 RDF files across these pods. The SolidBench dataset is derived from the LDBC Social Network Benchmark (SNB) [27], which provides a social network use case, in which people can be friends of each other, create posts, and like and comment on each others posts. Furthermore, we have pre-configured some of the SPARQL queries that SolidBench provides, which can then be executed over this simulated environment.
Our demonstration scenario will start by showing the SPARQL query “Discover 1.5” from SolidBench, which will produce all posts that are created by a specific person. For this, we will enable the Network inspection tool tab within the Chrome browser, which allows the audience to see the Resource Waterfall of all HTTP requests that were required to execute the query. This shows how some HTTP requests depend on other requests due to links between them, while other requests may be done in parallel. Fig. 4 shows a screenshot of this scenario.
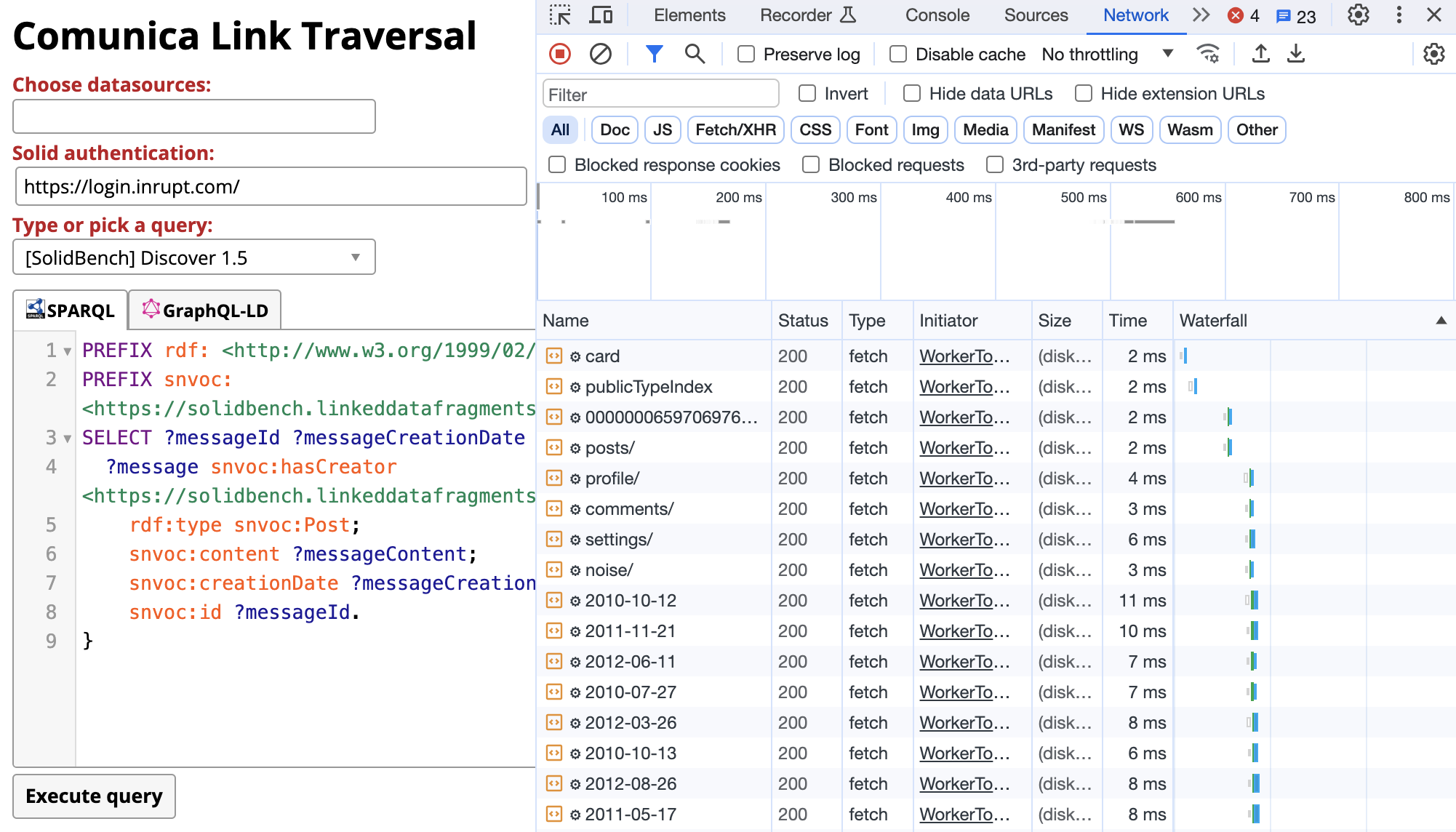
Fig. 4: The Resource Waterfall logs when executing Discover 1.5 from SolidBench.
Since “Discover 1.5” will primarily target a single Solid pod, we will also show “Discover 8.5”, which targets multiple Solid pods and will return all posts by authors of posts that a given person likes. In contrast to the previous query, “Discover 8.5” will traverse across multiple Solid pods, as shown in Fig. 5 Since this happens in a traversal-based manner, all of this happens automatically in the background without requiring any user interaction.
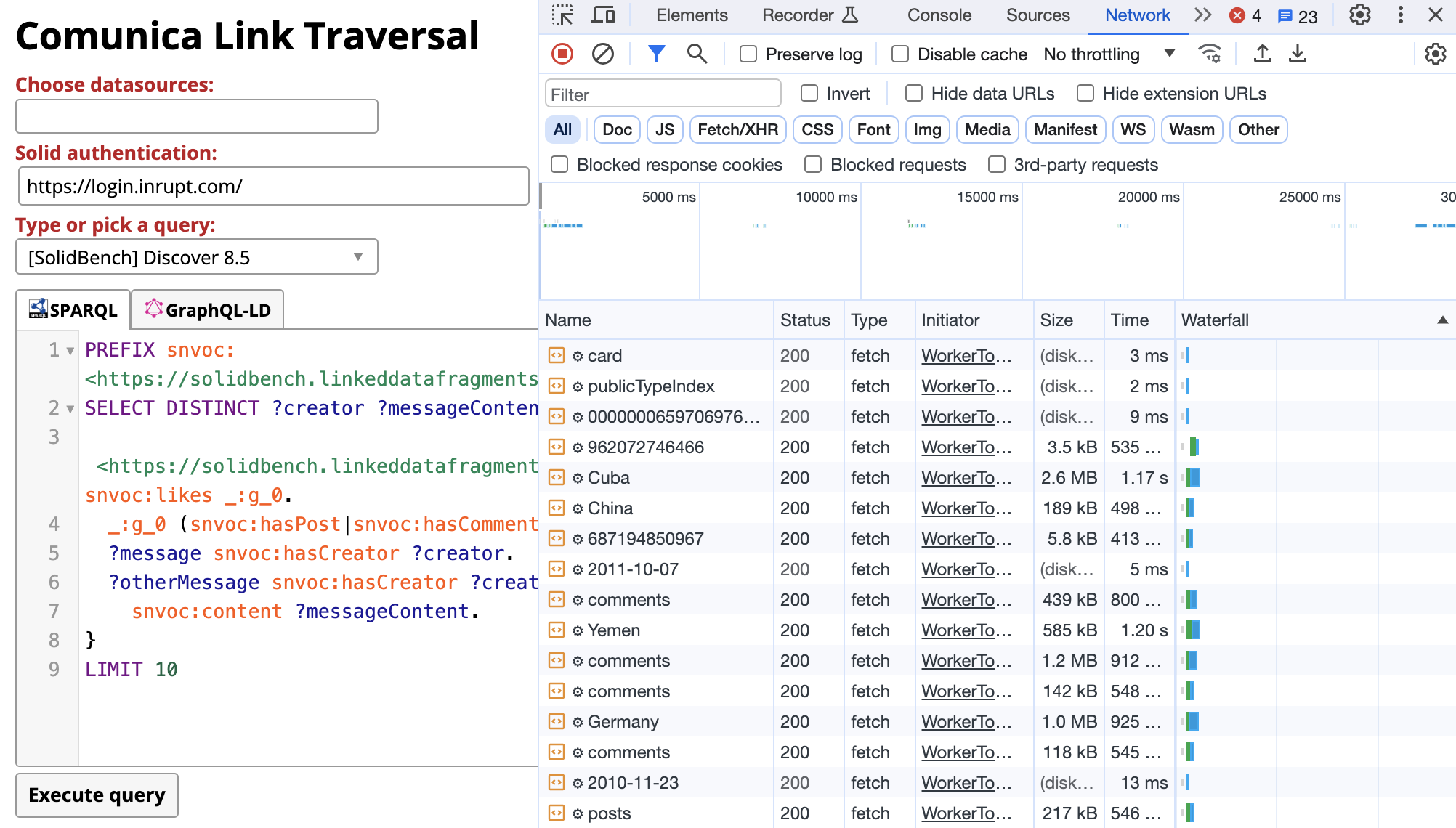
Fig. 5: The Resource Waterfall logs when executing Discover 8.5 from SolidBench.
Besides these 2 queries in the main demonstration scenario, we provide a total of 37 default queries that can be selected in the dropdown-list of queries.
Conclusions
In this article, we discussed the implementation of an open-source SPARQL query engine that is able to query over DKGs within Solid, a permissioned decentralization environment. Our system is based on LTQP techniques that were specifically designed for exploiting the structural properties of the Solid environment.
To demonstrate this system, we provide a Web-based user interface that can be accessed and used by anyone with a modern Web browser. We provide several default SPARQL queries that users can execute across simulated Solid pods, or users may write their own SPARQL queries for execution against real-world Solid pods. Besides this Web-based user interface, our system can be used within any TypeScript or JavaScript application, or via the command-line.
Through this demonstration, we show the effectiveness of traversal-based SPARQL query execution across DKGs. Many queries start producing results in less than a second, which is below the threshold for obstructive delay in human perception [28] in interactive applications. Our system and its demonstration provide groundwork for future research in traversal-based query processing over DKGs. In future work, we will investigate further optimizations, which may involve adaptive query planning techniques [29] –which have only seen limited adoption within LTQP [30] and SPARQL query processing [31, 32, 33]– or enhancements to the link queue [34].